


By Steve Smith
Senior BI Consultant at Stellar
Businesses often have a variety of sources of data including business applications, data feeds and file-based information stores; all of which contain valuable information. Analytics can help to extract value from these data sources. However, being able to access relevant data in one place can be challenging.
Traditional approaches typically involve centralising data into a data warehouse using extract, transform and load processes (ETL) to populate dimensional models. These processes can be slow, expensive to build and complex to maintain. With the platforms, they depend on, they are resource-constrained or inflexible to business demand.
Ability to query data across any source using a single, unified interface
To solve these shortcomings, a range of platforms have emerged. They provide the ability to query data across any source using a single, unified interface. You might know them as distributed query engines.
Distributed query engines connect to data stored in a wide range of sources. They include file-based data residing in data lakes and relational databases. Therefore, users can use a variety of interfaces to query the full range of data as if stored in a single database.
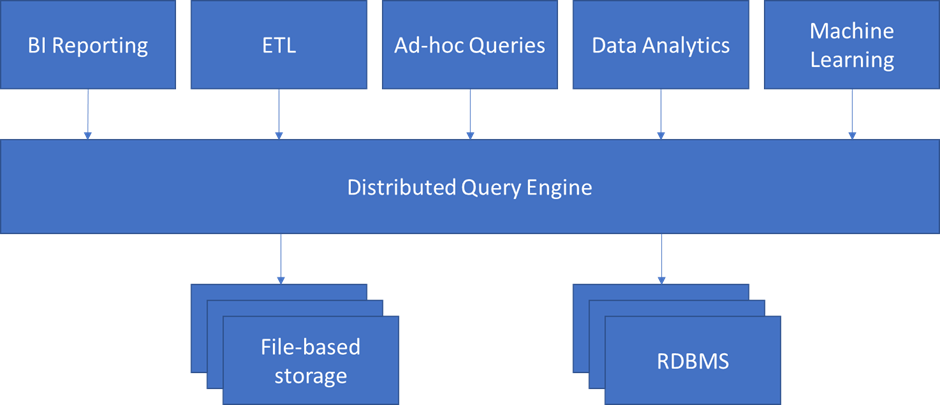
As their name suggests, distributed query engines run on a distributed architecture with a controller breaking down queries into smaller components for a cluster of worker nodes to process and execute, returning the consolidated result to the user. To ensure that the queries remain performant, the number of worker nodes can change dynamically to meet business demand and changes to the sources of data.
Above all, as data doesn’t need to be located in a database to be accessible, it can be stored in cheap online storage, such as Microsoft Azure Storage or Amazon S3. It provides cost and scale benefits over more expensive storage platforms.
More flexibility
This design provides more flexibility than platforms such as Snowflake, where data must be centralised before it can be queried by the query engine and does not offer the same range of sources. Distributed query engines are available as both open-source and commercial implementations; it depends on your requirements as a business.
Presto and Trino originated from the same codebase, with Starburst offering an enterprise-ready implementation. Dremio is based on Apache Arrow, implementing additional caching and file optimisation functionality to provide improved query performance.
The widely adopted analytics platform Databricks recently introduced their SQL Analytics capability, which a native SQL interface over lakehouse architectures, providing performance enhancements and compatibility with BI tools such as Power BI and Tableau.
The dedicated, scalable, flexible querying engine that integrates and leverages data, no matter where or how stored, has real power. It helps to reimagine the approach to analytics, data warehouses and BI. If you want to talk to someone about distributed query engines, contact Stellar!


