
 By Craig Larmer, Lead Consultant at Stellar
By Craig Larmer, Lead Consultant at Stellar
Researchers at Google have been looking at replacing traditional index structures in databases with data models created using machine learning (neural nets in this case).
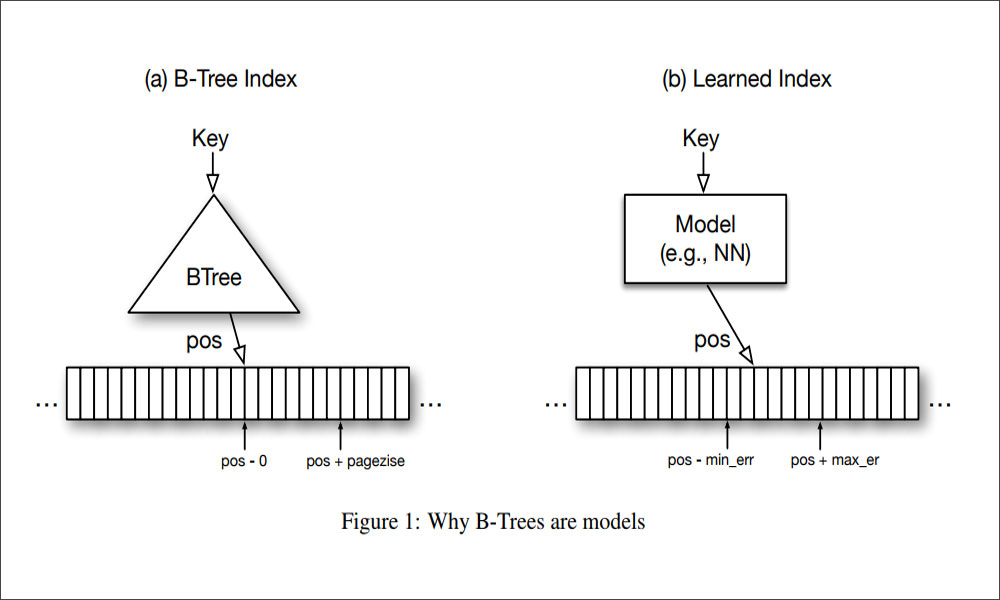
As they explain in The Case for Learned Index Structures, indexes are models. A B-Tree Index maps a key to the position of a record in a sorted array, a Hash Index maps a key to a position of a record in an unsorted array, and a BitMap Index indicates whether a data record exists or not.
The key idea is that a model can learn the sort order or structure of lookup keys and use this signal to effectively predict the position or existence of records. We theoretically analyse under which conditions learned indexes outperform traditional index structures and describe the main challenges in designing learned index structures.
The early findings look quite exciting.
Our initial results show, that by using neural nets we are able to outperform cache-optimised B-Trees by up to 70% in speed while saving an order-of-magnitude in memory over several real-world data sets. More importantly though, we believe that the idea of replacing core components of a data management system through learned models has far reaching implications for future systems designs and that this work just provides a glimpse of what might be possible.
Although this is still some way from becoming a commercial product, the research shows how machine learning can provide new solutions to old problems when used in a creative and innovative way.
Using a machine learning model as a data structure gives it all the properties of an index. The model effectively predicts the location of a row based on the key provided. B-Trees can do this by navigating a tree, but that takes a few steps, whereas machine learning can do it in just one step.
In this case, over-fitting the model is actually good, because the learned index doesn’t need to predict data not in the structure – which is often what we want to do when building a predictive model. Since we don’t need to know the exact position of a row (we just need to get to the nearest page) it’s perfectly suited to how relational data is stored.
This podcast provides a good introduction to the research findings. I suggest you fast forward to 1:07 to start the podcast.


