


By Steve Smith
Senior BI Consultant at Stellar
Data lakehouses are a data management architecture that combines data lake stores with the data management capabilities of data warehouses. They provide a cost-efficient, scalable, and resilient data platform suitable for BI and analytics.
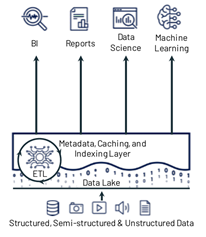
Structured data in a lakehouse is typically located in an online storage platform, such as Amazon S3 or Azure Data Lake Storage Gen2, using the Apache Parquet file format. Parquet stores data like a CSV, whilst also providing columnar compression and the schema metadata for the data it contains.
A metadata layer, such as the open source Delta Lake, is implemented over the data. It provides additional capabilities, such as ACID-compliant transactions, schema version management and time-travel, full transactional audit capability and data validation.
New query engines
To enable performant querying of the data, new query engines have been developed to provide a cost-effective, highly performant SQL-based query layer with automated data optimisation and tiered caching capabilities, the Databricks Delta Engine being a key example.
Analysts and data developers alike can query and manipulate data via the Databricks platform. It allows them to use different languages, for example, Python, Scala, R or SQL. Many popular ETL platforms are compatible with the Delta Lake format, with Talend Data Fabric, Azure Data Factory and AWS Glue among those already providing the capability to work with the files. Data scientists and machine learning engineers can use existing tools to access lakehouse data, thanks to the compatibility of tools like pandas or TensorFlow with the open data formats it uses.
Comparison
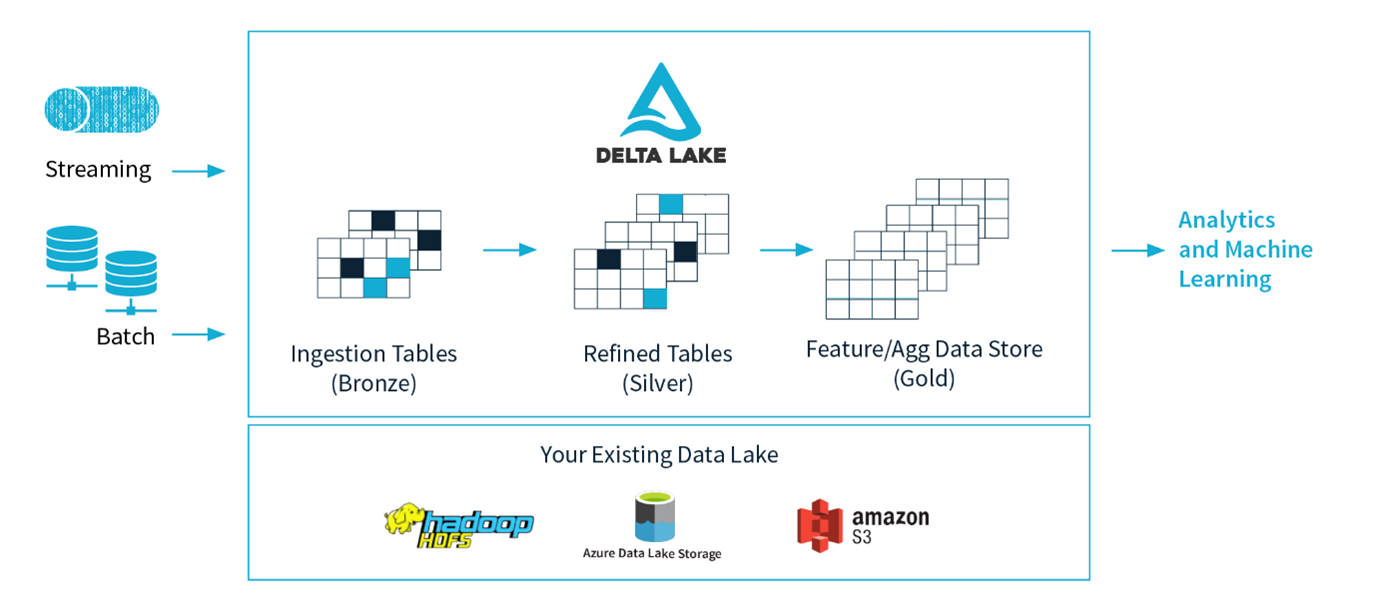
When compared to the cloud data warehouses from the major providers, the performance of the Delta Engine provides comparable or better performance than those platforms at a lower overall running cost. Data within a lakehouse is split into tiers that represent differing quality and usability attributes. The bronze layer is an unfiltered ingestion layer. It can obtain source data as quickly and easily as possible with no transformation. The silver layer introduces a level of refinement over the bronze data. It is cleaning, filtering, and augmenting the data for downstream use. The gold layer provides the business-facing model, with the silver data fully integrated, modelled and aggregated for business and analytic use.
The lakehouse architecture promises to be an exciting development. It will modernise existing data warehouse implementations, providing improved efficiency and reliability of data at a lower price point. If you want to know more about data lakehouses or need help with your BI and analytics, contact us at Stellar!
References


